jmh简介
JMH全称是 Java Microbenchmark Harness,是由JVM 性能工程师 Aleksey Shipilëv开发,作为 OpenJDK 的子项目之一,旨在微基准测试(官方定义为 nano/micro/milli/macro ,可见能做的不止是微基准测试)的工具套件,在 OpenJDK 9 后已被集成到JDK里 。
快速开始
由于大家基本上都是JDK8,所以需要引入类库的方式来使用。
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.35</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.35</version>
</dependency>
除了引入类库外,要打包成独立可执行jar包,还需要配置maven插件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<id>jmh-sample</id>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<finalName>jmh-sample</finalName>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- <mainClass>org.openjdk.jmh.Main</mainClass> 可以使用自己的入口,也可以使用jmh默认入口-->
<mainClass>study.benchmark.main.BenchmarkMain</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
<exclude>META-INF/maven/**</exclude>
<exclude>META-INF/services/**</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
如果依赖第三方类库比较多,但是运行时并不需要这么多类,则可以过滤来减少最终的fatjar的体积。
main入口可以使用自己的Main类,也可以使用jmh的Main,如果使用jmh的Main则需要在java -jar jmh-sample.jar的时候传入运行时参数。
基本概念
@BenchmarkMode 测试模式,可以用在测试类上,也可以用在方法上,可以有多个值:
- Throughput:吞吐量,意为单位时间内方法可执行的次数,如「1 秒内可以执行多少次调用」,该模式为默认值;
- AverageTime:平均时间,意为执行(单次)测试的平均耗时, 如「每次调用平均耗时多少毫秒」;
- SampleTime:随机取样时间,意为方法执行到某个完成度的耗时,例如「50% 的调用在多少毫秒以内,99.999% 的调用在多少毫秒以内」;
- SingleShotTime:单次执行时间,上述模式都是一个测试迭代( iteration )运行多次,该模式仅运行一次。往往配合关闭预热配置,用于测试冷启动时的性能;也可以用来配合bachsize指定方法执行确定的次数。
- All:测试会包含上述所有模式。
以上涉及到时间单位的定义,都可通过 @OutputTimeUnit 来配置测试报告中的呈现。
@Measurement 配置方法的执行,通过 iterations 可设置测试迭代的次数,每次迭代运行完后会串行的执行下一次。通过 time, timeUnit, batchSize 可分别控制每个迭代的时间,以及单次迭代的执行次数。
@Warmup 配置预热,为了达到最佳的测试结果,需要提前预热才行,预热的配置属性和@Measurement 基本一样。
@Threads 用来配置并发执行测试方法的线程数。
@State 注解的类,可以作为基准测试方法的参数注入,其作用域有三种
- Thread:该状态为每个线程独享,每个线程运行测试时都会创建自己的状态类实例;
- Group:该状态为同一个分组内所有线程共享,每个线程组运行测试时都会创建自己的状态类实例;
- Benchmark:该状态在所有线程间共享,所有线程共享状态类实例。
@Param 只能用在使用了@State 标注了的类属性上,而且参数类型仅能为基本类型及其包装类、java.lang.String、枚举;
@Setup和@Teardown则用在状态类的初始化和收尾工作,支持不同的执行级别
- Level.Trial:每次基准测试执行,其包括所有的预热迭代和测试迭代;默认级别
- Level.Iteration:每次测试迭代执行;
- Level.Invocation:每次测试方法被调用执行,谨慎使用。
@OperationsPerInvocation 用于告诉 JMH 测量方法中包含有几次操作,以便得到更精准的测量结论。例如需要测量一个循环中的单次执行性能。
@Benchmark
@OperationsPerInvocation(10)
public void test() {
for (int i = 0; i < 10; i++) {
// do something
}
}
代码示例
代码示例已经在Github上传,可以点击上述连接获取完整代码。
首先我们测试一下Random和ThreadLocalRandom的性能差别,大家都知道ThreadLocalRandom性能很快,但是没有概念比Random快多少,那我们就用基准测试来测一下。
package study.benchmark.random;
import org.openjdk.jmh.annotations.*;
import java.util.concurrent.TimeUnit;
/**
* @author wangdengwu
*/
@BenchmarkMode({Mode.AverageTime})
@Fork(1)
@Warmup(iterations = 1, time = 1)
@Measurement(iterations = 5, time = 2)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class RandomBenchmark {
@Benchmark
public int nextInt(RandomFactory factory) {
return factory.getRandom().nextInt(10);
}
@Benchmark
public int nextIntWithThreadLocal(RandomFactory factory) {
return factory.getThreadLocalRandom().nextInt(10);
}
}
我们关注平均时间,另外通过Fork进程的方式,来减少同一个JVM跑测试带来的影响。使用1秒钟的预热,每个基准方法执行5轮,每次2秒钟。
同时,我们使用了@State 依赖注入Random和ThreadLocalRandom。
package study.benchmark.random;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
import java.util.Random;
import java.util.concurrent.ThreadLocalRandom;
/**
* @author wangdengwu
*/
@State(Scope.Benchmark)
public class RandomFactory {
Random random;
ThreadLocalRandom threadLocalRandom;
public Random getRandom() {
return random;
}
public ThreadLocalRandom getThreadLocalRandom() {
return threadLocalRandom;
}
@Setup
public void init() {
random = new Random();
threadLocalRandom = ThreadLocalRandom.current();
}
}
Main函数入口代码
package study.benchmark.main;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import study.benchmark.random.RandomBenchmark;
import study.benchmark.string.StringBuilderBenchmark;
/**
* @author wangdengwu
*/
public class BenchmarkMain {
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.shouldFailOnError(true)
.shouldDoGC(true)
.jvmArgs("-Xmx1024m")
.threads(Runtime.getRuntime().availableProcessors())
.include(RandomBenchmark.class.getSimpleName())
.include(StringBuilderBenchmark.class.getSimpleName())
.resultFormat(ResultFormatType.JSON).build();
new Runner(opt).run();
}
}
我们还测试了不同拼接字符串工具类的性能,具体代码可以去Github查看,这里就不贴代码了。
如果配置好了maven的插件,使用mvn clean package即可打包出可执行jar包,jmh-sample.jar
执行java -jar jmh-sample.jar即可开始执行基准测试。执行完成后,有概要统计输出:
Do not assume the numbers tell you what you want them to tell.
Benchmark Mode Cnt Score Error Units
s.b.random.RandomBenchmark.nextInt avgt 5 957.973 ± 263.841 ns/op
s.b.random.RandomBenchmark.nextIntWithThreadLocal avgt 5 9.541 ± 1.324 ns/op
s.b.string.StringBuilderBenchmark.appendWithBuffer ss 10 97.373 ± 15.152 ms/op
s.b.string.StringBuilderBenchmark.appendWithBuilder ss 10 24.313 ± 18.410 ms/op
s.b.string.StringBuilderBenchmark.appendWithSynchronized ss 10 69.081 ± 35.567 ms/op
s.b.string.StringBuilderBenchmark.plus ss 10 3489.946 ± 134.923 ms/op
也会输出json格式的报表文件,通过可视化工具可以更直观的看到结果。
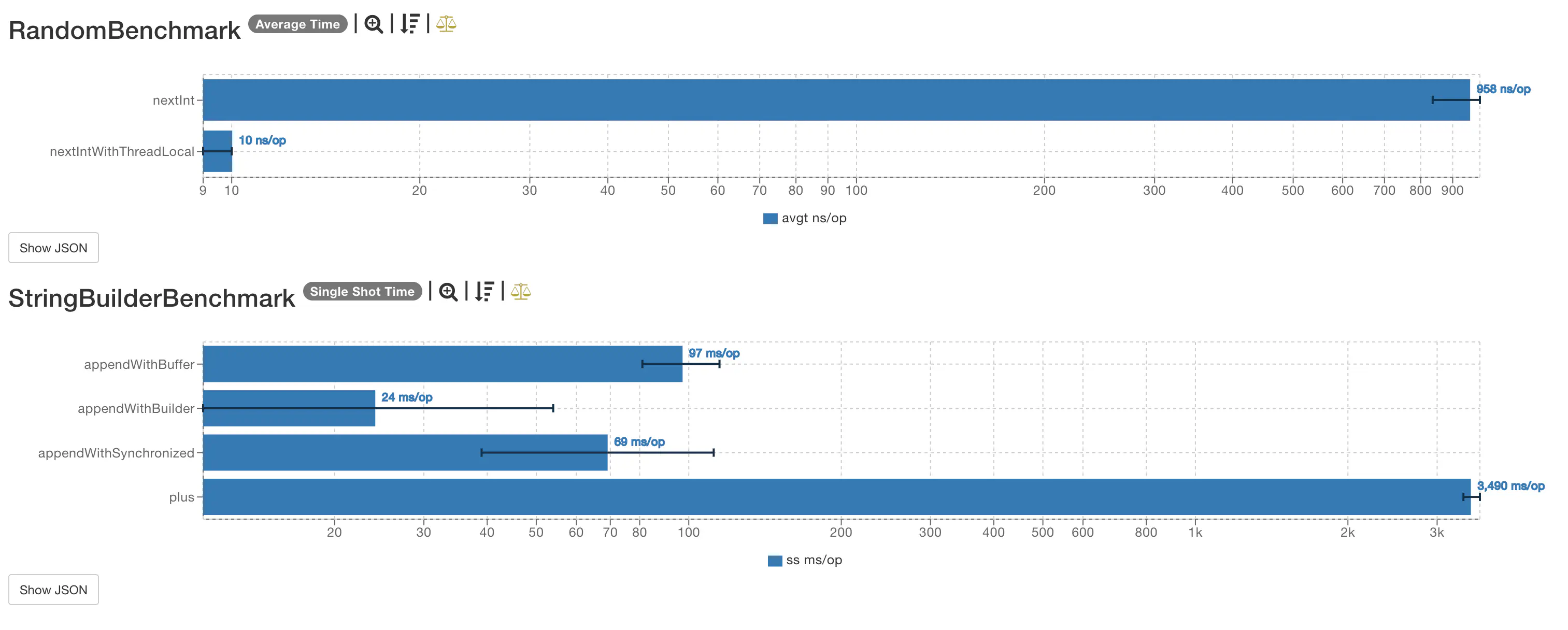
通过测试结果来看,ThreadLocalRandom和Random的差距在100倍,差距还是非常大的。
而字符串拼接这块,使用+来拼接,当数据量比较多的时候,性能非常差,而没有线程并发需求的情况下,StringBuilder性能最好,在并发情况下,使用synchronized同步StringBuilder比StringBuffer性能要好,因为
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
指定方法执行次数
当我们使用@Measurement(iterations = 5, time = 2) 指定基准测试方法时,只能配置迭代的次数和执行的时间,是不能指定方法被调用的次数的。
但是有时候我们就希望方法被测试次数可以指定,比如上面测试字符串拼接的方法,如果不指定次数,则在一定时间下,疯狂的字符串拼接将很容易导致oom,即使我们已经将jvm的内存设置成1G,依然很快就内存溢出了。
如何确切配置方法被执行的次数,一直困扰我,直到我从官方例子里发现了秘密,原来需要@BenchmarkMode(Mode.SingleShotTime)和@Measurement(iterations = 5, batchSize = 5000)配合才行。
实现原理
jmh的实现主要使用了2个技术点,基于注解的自动生成和JVM的fork功能。
注解的代码自动生成
/*
* Copyright (c) 2005, 2014, Oracle and/or its affiliates. All rights reserved.
* DO NOT ALTER OR REMOVE COPYRIGHT NOTICES OR THIS FILE HEADER.
*
* This code is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 only, as
* published by the Free Software Foundation. Oracle designates this
* particular file as subject to the "Classpath" exception as provided
* by Oracle in the LICENSE file that accompanied this code.
*
* This code is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License
* version 2 for more details (a copy is included in the LICENSE file that
* accompanied this code).
*
* You should have received a copy of the GNU General Public License version
* 2 along with this work; if not, write to the Free Software Foundation,
* Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA.
*
* Please contact Oracle, 500 Oracle Parkway, Redwood Shores, CA 94065 USA
* or visit www.oracle.com if you need additional information or have any
* questions.
*/
package org.openjdk.jmh.generators;
import org.openjdk.jmh.generators.annotations.APGeneratorDestinaton;
import org.openjdk.jmh.generators.annotations.APGeneratorSource;
import org.openjdk.jmh.generators.core.BenchmarkGenerator;
import org.openjdk.jmh.generators.core.GeneratorDestination;
import org.openjdk.jmh.generators.core.GeneratorSource;
import javax.annotation.processing.AbstractProcessor;
import javax.annotation.processing.RoundEnvironment;
import javax.annotation.processing.SupportedAnnotationTypes;
import javax.lang.model.SourceVersion;
import javax.lang.model.element.TypeElement;
import java.util.Set;
@SupportedAnnotationTypes("org.openjdk.jmh.annotations.*")
public class BenchmarkProcessor extends AbstractProcessor {
private final BenchmarkGenerator generator = new BenchmarkGenerator();
@Override
public SourceVersion getSupportedSourceVersion() {
// We may claim to support the latest version, since we are not using
// any version-specific extensions.
return SourceVersion.latest();
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
GeneratorSource source = new APGeneratorSource(roundEnv, processingEnv);
GeneratorDestination destination = new APGeneratorDestinaton(roundEnv, processingEnv);
if (!roundEnv.processingOver()) {
generator.generate(source, destination);
} else {
generator.complete(source, destination);
}
return true;
}
}
fork进程
fork这块主要使用了Java的process功能,入口在runBenchmarks方法,
for (ActionPlan r : plan) {
Multimap<BenchmarkParams, BenchmarkResult> res;
switch (r.getType()) {
case EMBEDDED:
res = runBenchmarksEmbedded(r);
break;
case FORKED:
res = runSeparate(r);
break;
default:
throw new IllegalStateException("Unknown action plan type: " + r.getType());
}
for (BenchmarkParams br : res.keys()) {
results.putAll(br, res.get(br));
}
}
如果使用了@Fork注解,则走runSeparate方法,而在runSeparate方法里,启动了BinaryLinkServer,用于fork出来的JVM通信。
然后调用了doFork方法,通过执行ProcessBuilder类,getForkedMainCommand返回的命令行指令。
ProcessBuilder pb = new ProcessBuilder(commandString);
Process p = pb.start();
注解示例
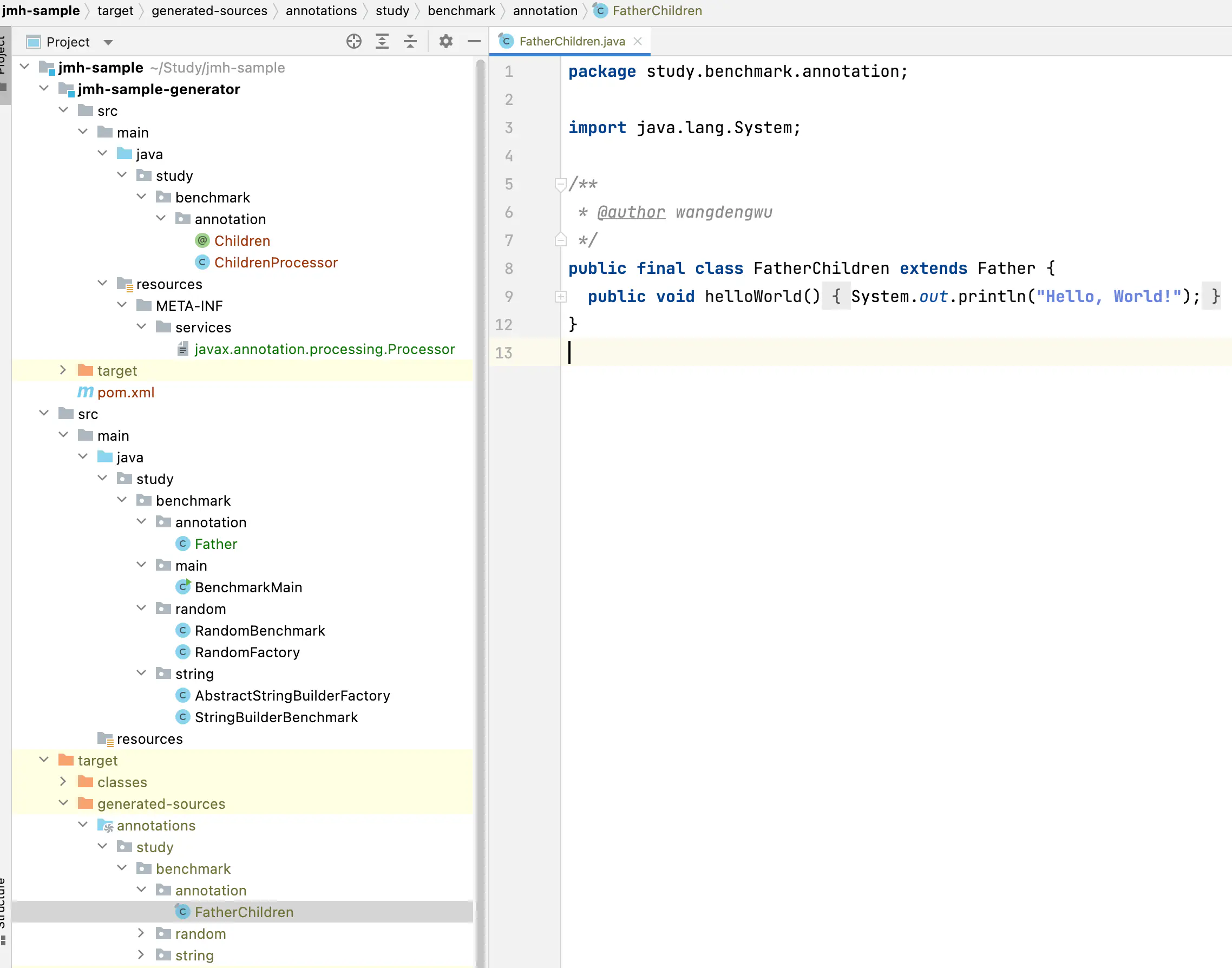
我们通过一个简单的@Children注解,来体验一下注解自动生成代码。
我们首先需要一个独立工程jmh-sample-generator,为了方便,我放在了jmh-sample下面,
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>study.benchmark</groupId>
<artifactId>jmh-sample-generator</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>jmh-sample-generator</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.squareup</groupId>
<artifactId>javapoet</artifactId>
<version>1.13.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<compilerVersion>1.7</compilerVersion>
<source>1.7</source>
<target>1.7</target>
<compilerArgument>-proc:none</compilerArgument>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.0.0-M5</version>
<configuration>
<useFile>false</useFile>
</configuration>
</plugin>
</plugins>
</build>
</project>
这里依赖了javapoet做代码生成,比较直观好用,不然自己使用writer写,和字符串打交道还是比较麻烦的。
然后需要添加<compilerArgument>-proc:none</compilerArgument>参数,否则mvn install的时候报错。
在resources下面,新建META-INF/services/javax.annotation.processing.Processor文件,内容为我们的ChildrenProcessor类全路径
study.benchmark.annotation.ChildrenProcessor
package study.benchmark.annotation;
import com.squareup.javapoet.CodeBlock;
import com.squareup.javapoet.JavaFile;
import com.squareup.javapoet.MethodSpec;
import com.squareup.javapoet.TypeSpec;
import javax.annotation.processing.*;
import javax.lang.model.SourceVersion;
import javax.lang.model.element.Element;
import javax.lang.model.element.ElementKind;
import javax.lang.model.element.Modifier;
import javax.lang.model.element.TypeElement;
import javax.lang.model.util.Elements;
import javax.lang.model.util.Types;
import javax.tools.Diagnostic;
import javax.tools.JavaFileObject;
import java.io.IOException;
import java.io.Writer;
import java.util.LinkedHashSet;
import java.util.Set;
/**
* @author wangdengwu
*/
@SupportedAnnotationTypes("study.benchmark.annotation.HelloWorld")
public class ChildrenProcessor extends AbstractProcessor {
public static final String SUFFIX = "Children";
private Types typeUtils;
private Elements elementUtils;
private Filer filer;
private Messager messager;
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
typeUtils = processingEnv.getTypeUtils();
elementUtils = processingEnv.getElementUtils();
filer = processingEnv.getFiler();
messager = processingEnv.getMessager();
}
@Override
public Set<String> getSupportedAnnotationTypes() {
Set<String> annotations = new LinkedHashSet<>();
annotations.add(Children.class.getCanonicalName());
return annotations;
}
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latest();
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
for (TypeElement annotation : annotations) {
for (Element element : roundEnv.getElementsAnnotatedWith(annotation)) {
if (element.getKind() != ElementKind.CLASS) {
messager.printMessage(Diagnostic.Kind.ERROR, "Only classes can be annotated with @Children", element);
}
String classPath = elementUtils.getPackageOf(element).getQualifiedName().toString() + "." + element.getSimpleName().toString() + SUFFIX;
MethodSpec helloWorldMethod = MethodSpec.methodBuilder("helloWorld")
.addModifiers(Modifier.PUBLIC)
.returns(void.class)
.addStatement("$T.out.println($S)", System.class, "Hello, World!")
.build();
TypeSpec children = TypeSpec.classBuilder(element.getSimpleName().toString() + SUFFIX)
.addJavadoc(CodeBlock.builder().add("@author wangdengwu").build())
.addModifiers(Modifier.PUBLIC, Modifier.FINAL)
.addMethod(helloWorldMethod)
.superclass(element.asType())
.build();
JavaFile javaFile = JavaFile.builder(elementUtils.getPackageOf(element).getQualifiedName().toString(), children).build();
try {
JavaFileObject sourceFile = filer.createSourceFile(classPath, element);
Writer writer = sourceFile.openWriter();
writer.write(javaFile.toString());
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return true;
}
}
package study.benchmark.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* @author wangdengwu
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Children {
}
代码不多,也很简单,就是根据有Children注解的类,自动生成带Children后缀的子类,并且生成了一个输出hello world的helloWorld方法。
然后mvn install打包到本地仓库,在jmh-sample的pom.xml里添加依赖
<dependency>
<groupId>study.benchmark</groupId>
<artifactId>jmh-sample-generator</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
新建一个类
package study.benchmark.annotation;
/**
* @author wangdengwu
*/
@Children
public class Father {
}
在jmh-sample工程下执行,mvn clean compile即可在target/generated-sources目录下看到生成的类FatherChildren.java